🛰️ Inside the Runway MCP — Live walkthrough June 25 > Register
🛰️ Inside the Runway MCP — Live walkthrough June 25 > Register
Use cases
Product
features
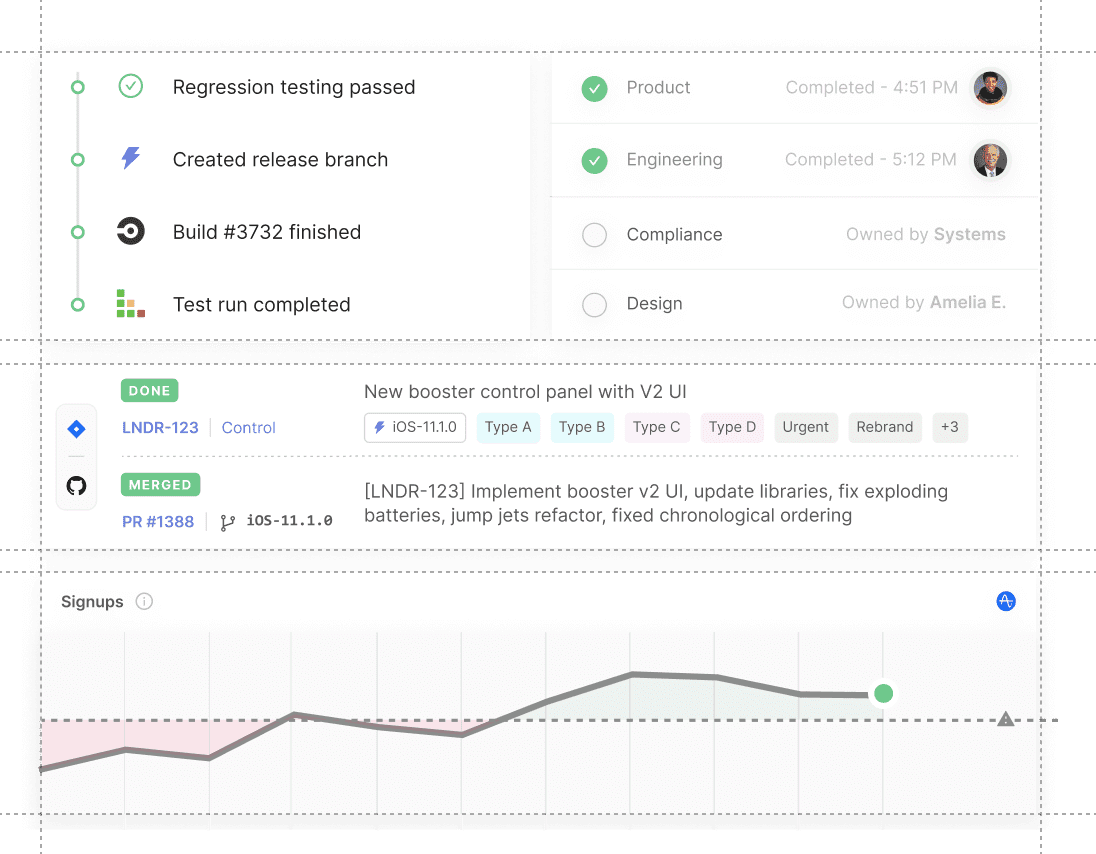
Release dashboard
Track release status
Collaboration tools
Centralize release comms
Automations
Automate manual tasks
App store management
Manage submissions and access
AI tools for mobile releases
Automate, analyze, safeguard
Security
Enterprise-grade data protection
features
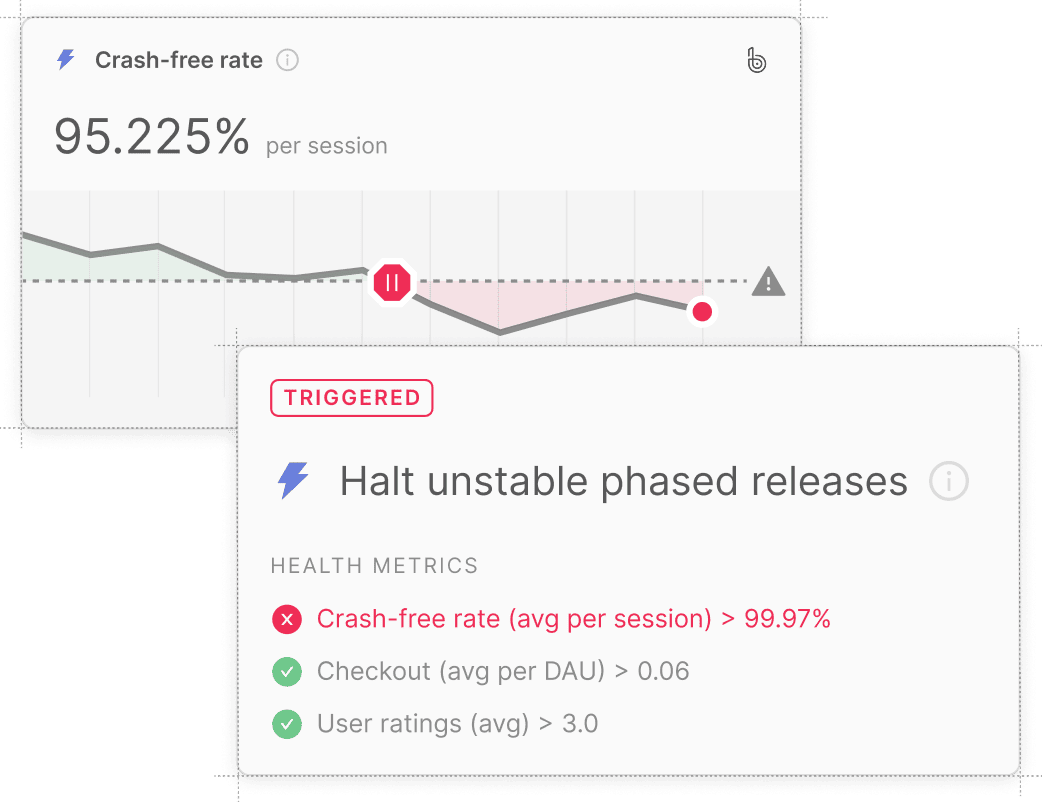
Rollout monitoring
Track rollout status
Flightpaths
Custom release workflows
Mobile rollbacks
Reverse releases fast
Feature readiness
See exactly what's happening
Fixes
Track late additions
Build Distro
Share builds easily
What's new
Integrations
Resources
Pricing